Em conferência promovida pelo IHU, professor revela suas estratégias no uso de IA e garante que essas novas ferramentas são fundamentais para preservação de ecossistemas
Se no passado o cientista era aquele sujeito que ia a campo e depois ficava meses trancafiado sozinho em seu laboratório fazendo as análises de dados coletados, hoje, ele tem de ser um sujeito conectado. É o que revela o professor Sergio Marconi, que aderiu plenamente ao uso de Inteligência Artificial – IA em suas pesquisas sobre florestas. Em conferência promovida pelo Instituto Humanitas Unisinos – IHU, dentro do “Ciclo de Estudos Inteligência Artificial, fronteiras tecnológicas e devires humanos”, Marconi revelou como até a coleta de dados no campo se transformou. “Até uns dez ou 20 anos atrás, era preciso selecionar um lote, possivelmente colocar algumas armadilhas nesse terreno para pegar esses animais. Imagine, por exemplo, uma pesquisa em que se estava tentando entender a população de espécies invasoras de roedores”, exemplifica.
E depois das armadilhas para apreensão de animais ainda tinha todo o trabalho de análise das amostras. Agora, essas armadilhas são ferramentas que tem como base a inteligência artificial. Isso facilita até mesmo velhas práticas, como colocar modernas armadilhas para fotografar espécies em seus habitats. Mesmo que se tivesse essa tecnologia, analisar as centenas de imagens geradas era um trabalho exaustivo. Hoje, programas baseados em inteligência artificial podem fazer desde mapeamento de áreas para análise, projeções dessas áreas para espaços maiores e até selecionar fotos e analisar imagens em vídeo em tempo real. “E esses algoritmos estão melhorando cada vez mais. A inteligência artificial ajuda não apenas fazer previsões em escala de árvores, mas também ajuda a entender quais são os fatores e processos potenciais que fazem com que as espécies sejam distribuídas”, exemplifica, a partir de suas práticas com florestas.
Tal qual foi o advento da técnica no cientificismo do século XIX, a evolução computacional na pesquisa científica permite um aprofundamento maior nas análises, gerando maior precisão e capacidade de projeção de cenários futuros. “Isso é importante porque, quando nós conseguirmos prever, poderemos utilizar sistemas de inteligência artificial para informar aos elaboradores de políticas e gestores algo que seja de interesse para poder preservar a natureza e a biodiversidade. Ao mesmo tempo, nos dá a capacidade de utilizar os recursos naturais para o que precisamos, pois precisamos crescer e sobreviver”, destaca Marconi.
Ao longo de toda sua fala, o professor traz usos dessas tecnologias em pesquisas tanto de fauna quanto de flora. Ao fim do encontro, ele ainda apresentou uma série de ferramentas que podem ser úteis, com infinitas aplicações em diversas pesquisas. Mas, se você acha que não domina essas ferramentas computacionais, o professor dá uma dica, especialmente para quem quer seguir trabalhando com ciência daqui para frente: “se você não tem uma ideia de como começar, de como programar, como começar? Bom, se você tiver a oportunidade de fazer uma aula de programação científica, faça”.


Sergio Marconi (Foto: Reprodução | Youtube)
Sergio Marconi atua na University of Florida, nos Estados Unidos. Possui pós-douturado em Recursos Florestais e Conservação e seu interesse científico se concentra em entender a relação entre diferentes atributos de plantas e a biogeografia dos táxons, e como essas relações se propagam na função do ecossistema e na biogeoquímica. Para fazer isso, ele usa visão computacional, técnicas de modelagem estatística determinística e multinível, para integrar informações ecológicas de sensoriamento remoto e levantamentos de campo em várias escalas.
Estou aqui para falar um pouquinho sobre a inteligência artificial em termos de preservação, tanto de animais, mas, especialmente, de plantas e do ecossistema de florestas. É o que tenho trabalhado há mais de dez anos.
Por que isso é importante? Nas últimas décadas, nós temos visto cada vez mais evidências de que estamos enfrentando desafios sem precedentes para poder sobreviver num ambiente que está em transformação, em termos de clima e dos recursos naturais. Isto porque a população global está cada vez maior e, de fato, precisamos de recursos. O problema é que, às vezes, nós abusamos desses recursos. Assim, acabamos cortando muitas árvores e não replantamos. Então, não é apenas um problema de clima, mas também um problema de uso de recursos em geral.
Estamos nos deparando com a mudança climática, mas também com problemas de uso da terra. E não podemos voltar, resetar, apertar o botão e, pronto, tudo vai estar bem.
Nesse momento não podemos encontrar uma forma exata de entender quais são os efeitos potenciais de padrões futuros no clima e na distribuição dos recursos naturais para podemos, de fato, administrar nossa própria sociedade e nos adaptarmos. O núcleo da minha pesquisa é tentar entender como nós podemos compreender melhor os sistemas nacionais naturais para prevermos a dinâmica desses sistemas e podermos fazer um bom manejo da preservação da biodiversidade e fazer o sequestro de carbono.
Para chegar lá é muito complicado, porque não se trata apenas de um modelo para se entender teoricamente como funciona sistema ecológico. É uma questão que chamo de tríade, como na imagem abaixo.
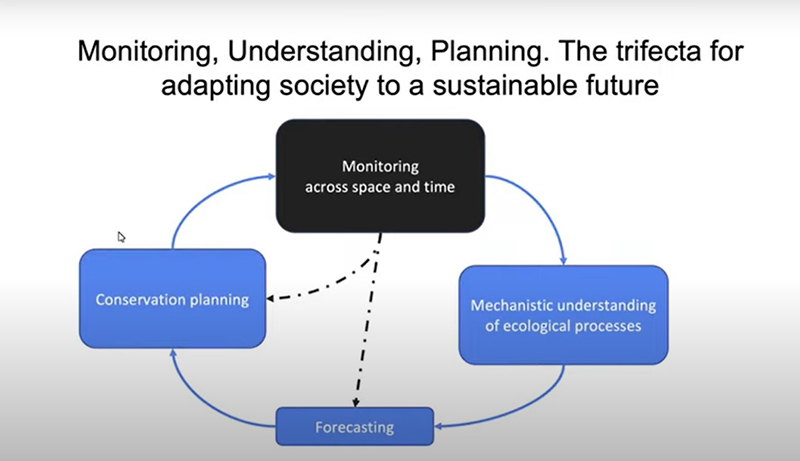
As imagens são reproduções da apresentação do professor
Não podemos administrar as coisas que não medimos. Para termos formas baratas e escaláveis de quantificar quais são os recursos e as propriedades dos ecossistemas das florestas ou da vida animal, podemos, em tempo real, obter uma forma de medir sistemas numa escala bastante grande. Mas, nem sempre temos uma oportunidade para ver, por exemplo, padrões de biodiversidade ou padrões de diversidade de espécies, como padrões imigração de pássaros, e depois imaginar como podemos traduzidos dados em processos. Ou seja, quando temos uma quantidade de dados temos que pensar qual é a natureza subjacente dos ecossistemas.
E aí nós podemos utilizar essas propriedades e regras e teorias para de fato ter um olhar no futuro e potencialmente entender, por exemplo, qual o aumento da temperatura ou a precipitação que pode afetar a distribuição relativa de uma espécie que é importante no seu cenário. Ou, ainda, invasão de outras espécies ou o potencial do incêndio para determinar a distribuição desses recursos numa determinada região.
Isso é importante porque, quando nós conseguirmos prever, poderemos utilizar sistemas de inteligência artificial para informar aos elaboradores de políticas e gestores algo que seja de interesse comum para poder preservar a natureza e a biodiversidade, preservando os recursos naturais. Ao mesmo tempo, nos dá a capacidade de utilizar os recursos naturais para o que precisamos, pois precisamos crescer e sobreviver.
Esse alinhamento pode ser dado pelos sistemas de Inteligência Artificial – IA, que interagem com os humanos e os agentes públicos precisam se voltar para esse sistema de monitoramento. Temos que nos certificar de que as ideias de manejo que construímos juntos com IA de fato estão alinhadas com aquilo que estamos tentando obter, que é a preservação. Isso é bastante complicado, eu já modelei esse estudo para os próximos 20 anos na nossa universidade, mas fica ainda mais complicado porque a ecologia é uma área que depende de escalas.
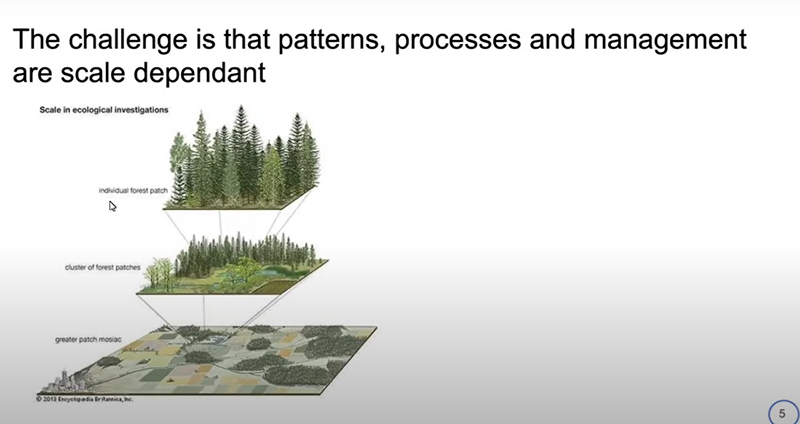
Se vocês estão analisando padrões para elaborar um ecossistema particular, como uma floresta, imagine que vocês estão passando por essa floresta num parque. Nesse caso, verão algumas propriedades bem específicas que dependem de processos ecológicos particulares. Mas, se forem para casa e olharem no Google Earth, verão que as propriedades emergentes desse ecossistema são muito diferentes, dependendo da escala em que estamos nesse sistema natural. E isso também é porque muitos dos nossos processos e propriedades ecológicas se tornam mais importantes do que outros. Então, a competição entre as árvores e muito mais importantes num fragmento, num detalhe, numa escala menor.
De que forma realmente nós vamos tentar ensinar a nós mesmos e aos elaboradores de políticas públicas, os agentes públicos, como administrar e manejar um terreno com floresta? O problema é que as escalas não são sistemas fechados, há uma forma de interagir com esses processos ecológicos e propriedades também comunicando entre as escalas. Tem algumas propriedades, imagens que vêm de uma parte, um fragmento de floresta específico, que tem uma escala continental de padrão. Nesses processos também podem ser dimensionados para propriedades particulares que nós vemos num fragmento específico de floresta, como a mata de um parque, por exemplo [observe essa relação na imagem abaixo].
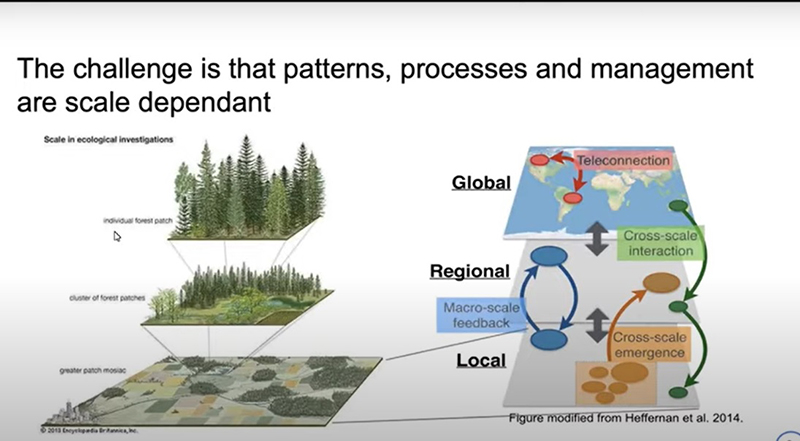
E o que torna essa análise mais difícil ainda é que nós não temos dados para resolver esses problemas em pontos tão pequenos, tão específicos. Isto porque, quando tentamos obter dados nossos sistemas, somos forçados a utilizar formas bem variadas e coletar dados. Por exemplo, na minha formação estudei sobre florestas e quando eu comecei obter informações de florestas íamos no campo, selecionava um ponto específico, colhia todas as informações das plantas naquele pequeno fragmento, aquele terreno, digamos, 200 m². Mas há uma outra área com vários sistemas, outros terrenos que acabávamos desconsiderando. É verdade que com a análise de apenas uma parte, possivelmente, se terá informações suficientes sobre o ecossistema e, basicamente, pode utilizar isso para prever a produtividade das do ecossistema da sua floresta.
O problema, entretanto, é que se você fizer uma projeção ainda maior, de um terreno maior, de forma mais rápida a coleta desses dados fica muito cara. E se torna muito insuficiente responder essas perguntas, especialmente se vocês estão tentando entender os padrões ecológicos entre as escalas. Observe a comparação na imagem abaixo.

O mesmo vale para os animais. Até uns dez ou 20 anos atrás, era preciso selecionar um lote, possivelmente colocar algumas armadilhas nesse terreno para pegar esses animais. Imagine, por exemplo, uma pesquisa em que se estava tentando entender a população de espécies invasoras de roedores. Até se poderia colocar um GPS nessas armadilhas, mas era muito caro. Realmente, não se tinha uma forma de dimensionar isso para todo uma grande área como continente ou um país. Mesmo em um município é muito difícil ter isso ter esse conjunto de dados macro ecológicos em grande escala a partir desse sistema de armadilhas para captura de animais em uma pequena área.
No entanto, especialmente nos últimos dez anos, melhoramos cada vez mais em tecnologia de coleta de dados, tanto via satélites quanto aviões e drones. Os drones, inclusive, estão mais acessíveis agora tanto para cientistas como também para pessoas comuns. Se pode, assim, de maneira efetiva, voar sobre uma região especial e tirar fotos, e essas fotos podem ser um conjunto de números, mas também respondem muitas informações, especialmente de informações sobre recursos naturais.
O problema é que todas essas informações, sem IA, ou uma forma de se traduzir números em propriedades ecológicas nas quais vocês estão interessados tudo parece não ser possível fazer relações. Mas, se vocês puderem obter através da IA uma forma para traduzir informações em informações ecológicas podemos explorar lotes continuamente nessa região através de fotos.
O trabalho que eu tenho feito já nos últimos anos é como essas duas tecnologias, o sensoriamento remoto e a inteligência artificial. Elas são inovadoras para a preservação do ecossistema e florestas, mas, também sistemas agrícolas.
Vamos começar com animais. Há alguns anos, se vocês quisessem colher informações sobre a fauna, geralmente era um processo muito caro, porque vocês precisavam ter um designer de amostra, ver uma população e encontrar dados para essa população. Se poderia obter a armadilhas para camundongos, mas aí já fica difícil se estivesse estudando uma espécie de onça, felino grande. Uma solução inovadora para a ecologia dos animais selvagens é utilizar essa ideia de sensores de movimento e colocar numa câmera na natureza. Quando houver movimento diante dessa câmera, ela vai tirar uma foto. Qualquer animal que passar na frente da câmera, tira uma foto. Isso é inovador porque você não se limita apenas aos traços, pegadas e outros elementos deixados pelas espécies. Basta instalar a câmera e uma vez por mês, por exemplo, vocês vão lá ver essas imagens.
O problema é que a parte inovadora de ter esse sensoriamento remoto para tirar fotos automáticas de animais na natureza não resolve o problema dos estudantes de doutorado ou de mestrado. Eles têm que voltar para casa e escanear a milhares de imagens. Talvez a metade tenham que ser apagadas porque um galho caiu, uma folha caiu e a câmera tirou uma foto que não é importante para a pesquisa. Além disso, pode haver uma informação que não fica fácil de perceber, pois o animal pode até estar lá no conjunto das imagens, mas como se tem centenas de imagens não consegue ver o animal. Então, para evitar tudo isso, utilizamos IA para identificar e classificar objetos na forma de imagem.

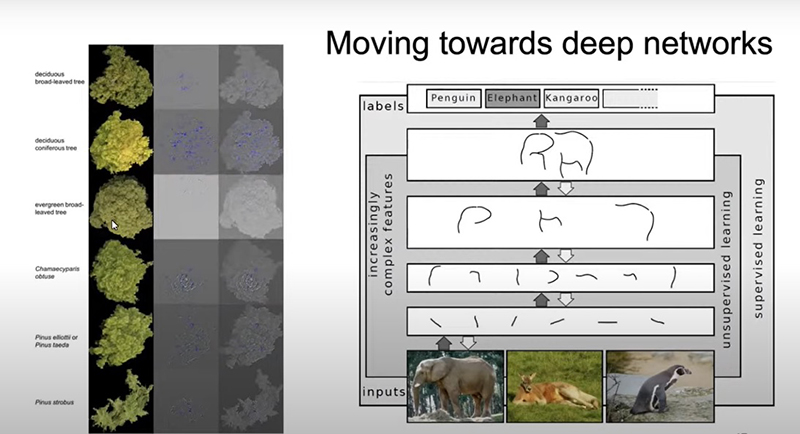
Isso aí [imagem acima] significa que todos os algoritmos de IA estão tentando imitar a visão em humana para de fato entender qual é o contexto dentro de uma imagem em particular. E as classificações de imagens já está aí há bastante tempo, mas particularmente na última década, o uso de deep learning profundada e essas redes neurais convolucionais são muito mais poderosas do que as abordagens de aprendizado de máquina utilizado até então.

Se eu perguntar que tipo de animal está aí [na imagem acima], vocês podem identificar que isso é um elefante. E se vocês tentarem decompor para explicar por que é um elefante e não um canguru, provavelmente vocês vão me responder que podem ver as grandes orelhas ou a tromba. Há a forma como funciona o olho humano, como nós enxergamos um objeto, mas o cérebro reconhece a hierarquia e as hierarquias entre as características é que reconhecemos que esse objeto é um elefante, composto de certas unidades ou orelhas os olhos, a tromba, etc.
No entanto, a subunidades também são compostas de outras subunidades. Como se reconhece uma orelha? Porque parece como um semi-círculo e um triângulo acima, por exemplo. Se nós pudermos ter de fazer com que os computadores enxerguem da mesma maneira, potencialmente podemos fazer com que os computadores entendessem conceitos abstratos. E, a partir disso, distingui que não se trata de um canguru ou um pinguim e sim de um elefante.

Como nós podemos fazer com que um computador pense da mesma forma que um humano? Quando nós pensamos sobre uma imagem, ou quando eu estava falando sobre o sensoriamento, realmente que você estão olhando a matriz de números apenas. Vocês não precisam seguir o cálculo matemático, mas essencialmente, a ideia é que vocês têm um retângulo onde cada pixel que você vem é atribuído a um número. Então, se você tiver uma pequena matriz que chamamos de filtro, por exemplo, e essa matriz pequena, vocês têm algum conjunto específico de números. Basicamente, se multiplica cada número na sua imagem por esse pequeno filtro. O resultado não é a imagem do mesmo tamanho da primeira imagem, mas uma transformação dessa imagem dependendo desses números. Se escolherem um conjunto de números diferentes, terão resultados bem diferentes na imagem.

Por exemplo, quando vocês estão verificando o telefone celular de vocês e querem aumentar a nitidez da imagem, o seu telefone está multiplicando através desse filtro de nitidez cada pixel, e isso vai destacar a borda da imagem e vai parecer mais nítida.
A ideia é que se nós soubermos suficiente sobre a diferença de entre um elefante e um canguru poderemos encontrar filtros específicos que vão fazer com que essa imagem original, que é o elefante, seja muito diferente no gráfico da forma de um canguru. E aí se pode sobrepor filtros e utilizar num algoritmo de aprendizagem de máquina, e basicamente através da utilização da sequência de número, vai se distinguir que a imagem é de um elefante e não de um canguru.
Se nós vamos ter esses filtros, aquela matriz, talvez façamos um bom trabalho para identificar o elefante que sempre parece com um elefante. O problema é quando nós tentamos pensar em ter um modelo para prever cada possível objeto que está numa imagem. Se teria que ser um especialista em elefantes, em carros e girafas, em árvores. Rapidamente percebemos que se torna impossível fazer uma engenharia de características de uma forma manual, precisamos de uma forma de fazer isso automaticamente. E é aí que a visão computacional e IA de fato transformam o campo numa forma incrível.
Qual é a ideia dessas redes neurais convolucionais? Uma das visões das arquiteturas de visão computacional da IA, se fato esquecer o que está dentro desse filtro em particular, vocês podem dizer para um computador que se quer utilizar sete filtros e não apenas um e que se quer fazer isso sequencialmente três vezes. O computador vai ver qual é o número que tem que estar nesses filtros para que eu possa classificar todos esses objetos para os quais eu tenho imagem.
O que está acontecendo é que vocês podem fazer com que o computador aprenda dando ao mesmo computador dados suficientes para começar e ver como deve ser um elefante, como deve ser um carro, um canguru, etc. O computador, então, sequencialmente, vai tentar entender quais são esses filtros que fazem esses padrões e que dão essas estruturas de características hierárquicas, da mesma forma como o seu cérebro vê um carro e um outro carro e que abstrai informações sobre um carro.

Com essa ideia, podemos ter com uma infraestrutura bem semelhante para vários problemas possíveis. Podemos utilizar o mesmo tipo de arquitetura, podemos utilizar as redes neurais convolucionais para ir e identificar árvores ou todas as aves que estão na imagem. Podemos, ainda, ter uma visão computacional, a partir dessas redes neurais convolucionais, para identificar algum animal dentro de uma imagem com vários animais e delinear um determinado animal. É o que mostramos nessa imagem do meio colorida, em que delimite o que é uma zebra [na figura acima].
E o que é incrível é que também se pode processar ruidos, informações vocais. Assim, podemos transformar os padrões de canto de pássaros em imagens e você pode utilizar essas imagens para aprender qual a assinatura de canto de um pássaro específico e, a partir daí, pode ter previsões de que tipo de pássaros estão ali. Ou seja, não apenas vê-los, mas também ouvi-los cantando.
Esta rede convolucional que eu mostrei a vocês é basicamente a ideia que se tem de uma imagem de um animal, e isso lhes dá um output. E se houver mais de um animal ou mais de um objeto na imagem se tem a evolução dessa rede neural convolucional, que é a R-CNN, da imagem abaixo.
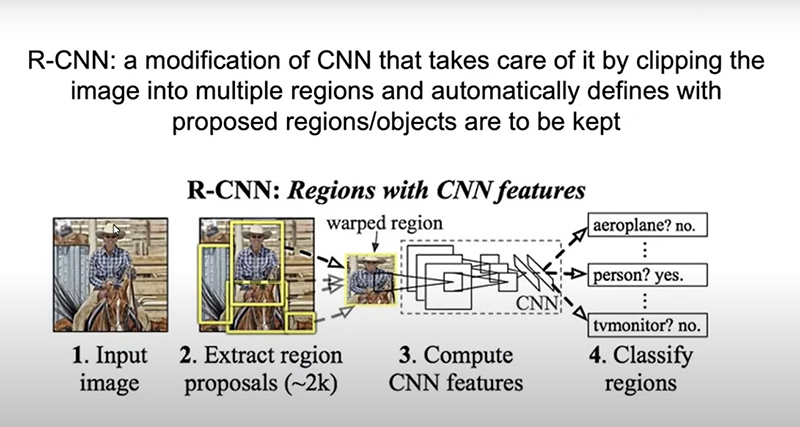
Ela basicamente obtém ou divide a imagem em várias subimagens aleatórias [ilustração acima] e aí nós temos que ver se cada uma delas de fato é um objeto. E essas arquiteturas originalmente estão muito dentro da imagem. É incrível que nos últimos anos essa abordagem ficou cada vez mais inteligente, mais rápida e agora vocês podem obter a detecção de um animal e a classificação deste animal até mesmo passando num vídeo em tempo real. Vocês podem testar isso usando o Yolo5 [como o vídeo abaixo demonstra].
Isso é extremamente útil para a preservação, porque significa que vocês podem ter uma câmera de vídeo num drone, voar com esse drone e ver um animal em movimento ao vivo. Isso é incrível comparado com o que costumávamos fazer alguns anos armando armadilhas para encontrar as imagens da animais só um mês depois.
É possível fazer isso não apenas com vídeo, mas com fotos. Vocês podem ter um drone voando, tirando fotos e, em tempo real, buscando respostas referentes a migração de pássaros ou movimentos imigrações de mamíferos. O céu é o limite. Se tiverem dados com muito boa resolução, podem responder várias perguntas.
E vocês podem também fazer com que sistemas de IA aprendam qual é a relação entre pontos particulares no corpo e, a partir daí, aprender padrões de movimentos de mamíferos. Podem utilizar isso, por exemplo, ao tentar entender quais são os padrões de interações entre mamíferos. Se pode obter informações em tempo real de basicamente tudo o que imaginarem.
No caso das plantas é mais fácil, pois elas não se movimentam como os animais. Se você for analisar um organismo bastante grande, como uma árvore, pode obter dados de diferentes pontos do tempo. Vocês podem ver [na imagem abaixo] que uma árvore individual mudou.
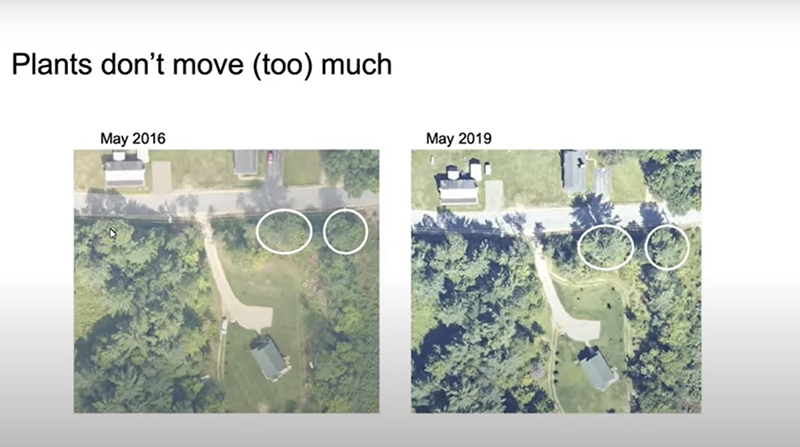
A partir disso, podem responder a diversas perguntas sobre desmatamento ou infestação, por exemplo, de patógenos que podem matar determinada floresta. Primeiro, é preciso imagens que podem utilizar dados de drone ou satélites, dependendo das informações que vocês obtêm. Mas, é preciso imaginar como transformar essas imagens para detectar uma árvore e obter informações desta árvore, como a quantidade de carbono armazenada em seu interior.
Para chegar lá, é preciso fazer algo muito semelhante aos passos que nós vimos para os animais, começando pela detecção. A detecção gera um problema em que nós não precisamos saber qual o tamanho do objeto. Não precisamos saber qual é a propriedade exata do objeto. Só precisamos saber se esse objeto está lá ou não. No caso de uma árvore, a detecção é numa cena em particular, onde nós temos centenas de árvores, mas também temos prédios, a floresta, flores, etc. O que torna essa árvore individual diferente de uma outra árvore individual? Para isso, vamos fazer o delineamento, que é um outro problema, de um IA: quando se sabe o que é uma árvore, qual é o tamanho dessa árvore específica comparada com as outras árvores? Onde você resolve a questão de detecção e delineamento você tem alguns polígonos que podem ligar com seus dados de campo.
Então, se vai a campo, olha dados para se obter informações de campo colendo dados em lotes e aí o sistema de IA vai traduzir as informações dos pixels em informações que são informações ecológicas. É assim que nós construirmos esse modelo, se tivermos a identidade de espécies e a quantidade de oxigênio nas folhas ou a saúde dessa árvore, nós não precisamos mais de dados de campo, porque podemos obter as imagens e fazer previsões.
E todas as imagens para todas as árvores que nós detectamos e delineamos para um conjunto de dados original de 200 árvores individuais, podemos obter facilmente obter conjunto de dezenas ou milhões de árvores.
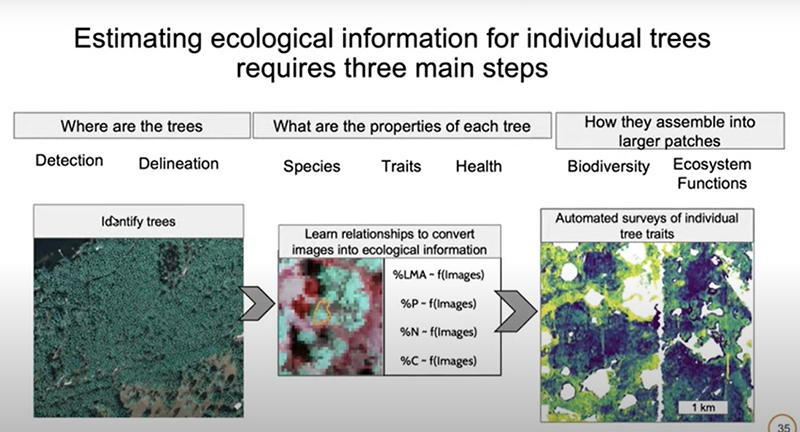
Significa que vocês podem começar a responder perguntas sobre a dinâmica da relação entre a interação entre árvores, a relação entre a topografia e a quantidade de nitrogênio dentro de um lote específico, e assim por diante.
Que tipo de dados precisamos para chegar lá?
Vamos utilizar três tipos de dados:
- Um é o Lidar Kid, uma forma de se calcular de maneira eficaz as estruturas tridimensionais da floresta.
- O outro são os dados RGB, que vocês estão acostumados a ver quando tiram fotos, que é uma matriz em três dimensões, vermelho, verde, azul, que lhes dão a percepção de cores.
- E o terceiro são dados hiperespectrais, que é semelhante ao RGB, mas ao invés de ter três canais, vermelho, azul e verde, temos 26 canais. Isso é inimaginável em termos de cores.

A vantagem do RGB com relação ao hiperespectral é que tendo somente três canais é muito fácil de se ter uma resolução apenas passando os olhos nos dados, porque é uma tarefa fácil para o sensor. É basicamente obter informações, só precisa gravar três vezes. Significa que nós podemos obter detalhes de informações geométricas de todas as árvores individuais. É quando é possível ver o que é uma árvore aqui em comparação com as outras, ao passo que é um pouco mais difícil quando você tenta fazer com dados hiperespectrais.

Esses dados hiperespectrais tem que recolher informações por tantas porções pequenas da refletância espectral e precisa obter mais luz, ou seja, precisa ter uma resolução geométrica mais ampla. O que se está perdendo em termos de qualidade na resolução, se ganha em termos de qualidade da resolução radiométrica. Basicamente, se vai entender quais são as informações dentro de um pixel em particular em termos da quantidade de madeira ou de nitrogênio ou de folhas em comparação com o solo, por exemplo.
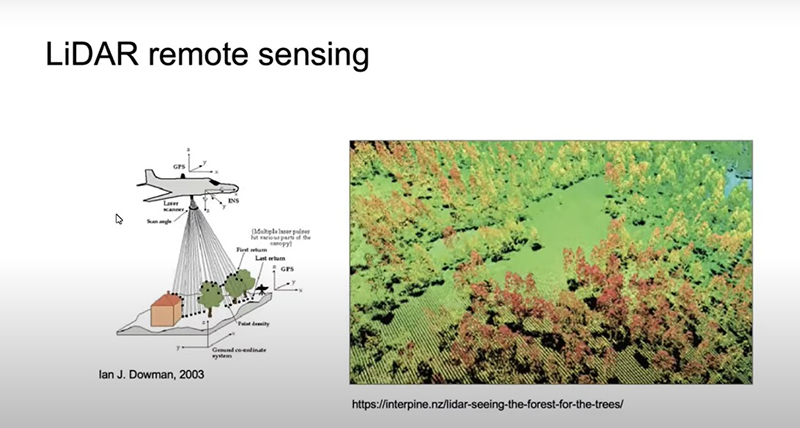
O Lidar é um dado unidimensional, mas ele é diferente de um tipo de imagem onde você tira uma foto e tem pixel. O Lidar é um é um sensor e joga um fecho de luz como uma bola de tênis [veja o gráfico na imagem acima]. E quando essa bola volta para o sensor, calcula, em termos de tempo, e diz que para aquele ponto qual é a diferença em altura e permite que se tenha estruturas tridimensionais, se tiver pontos suficientes para começar. E, dependendo de cada um desses conjuntos de dados, nós temos vantagens e limitações diferentes.
Então, os dados Lidar e os dados RGB, por exemplo, são extremamente valiosos para se obter informações sobre a detecção e delineamento de árvores. Isto porque ele nos dá estruturas de dimensionais muito boas de florestas. Se vocês pensarem sobre uma árvore, vocês esperam que a árvore seja algo como uma parte superior, e aí e desce. Realmente não se vê muito mais. Se observarmos o globo, podemos desenhar um círculo ao redor dessa copa e afirma que isso é uma árvore. A vantagem é que você não precisa de mais dados para fazer uma previsão, porque o que a IA e algoritmo podem fazer é uma rodagem não supervisionada que vai utilizar a relação bidimensional imaginar, utilizando algumas regras, como deve ser essa árvore.
O problema é que se você tiver uma área muito povoada, com as copas das árvores se tocando, o algoritmo vai entender como uma árvore apenas ou uma árvore com dois galhos enormes. Como resolver esse problema?
Vocês podem utilizar esses formatos pontiagudos das árvores para se obter algo mais ou menos como uma nuvem pontiaguda, onde cada árvore individual é apresentada e está associada a um indivíduo único.
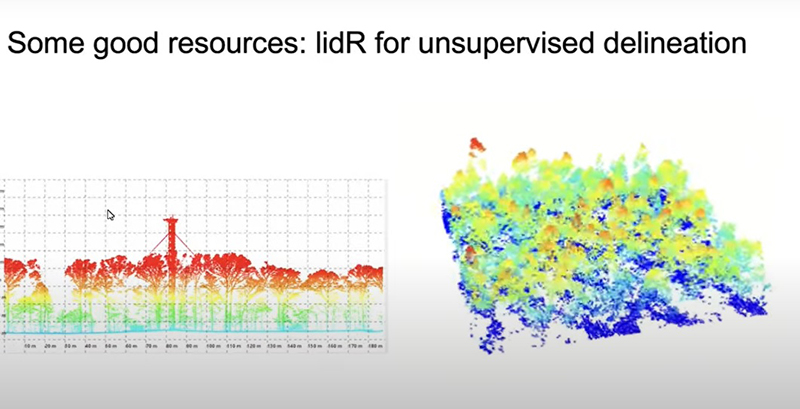
E podemos utilizar esses indivíduos para construir polígonos e transformá-los em quadrados que são uma árvore ou ao redor de um objeto que pode ser utilizado para treinar um modelo de IA como aquele para os animais.
Porém, se nós não temos dados suficientes para começar, utilizarmos essa Lidar para abordagem supervisionada não é ideal. Embora ele nos dê informações sobre o que é uma árvore e utilizamos esses rótulos para treinar modelos de IA e milhões dessas árvores. E aí podemos fazer, então, previsões que são melhores para árvores individuais, numa escala utilizando dados do RGB, que é o mais abundantemente disponível e provavelmente vocês vão poder utilizar em qualquer lugar em todo o mundo.
E aí, se vocês quiserem chegar ao polígono e entender tanto dentro dessa caixa qual é o formato de uma copa e se querem entender qual é a espécie dessa copa, novamente podem utilizar essa rede neural convolucional [demonstrada na imagem acima] para ter uma ideia de qual é a hierarquia das relações e se pode identificar qual é a estrutura potencial de um pinheiro em comparação com carvalho, por exemplo.
Se vocês querem tentar separar pinheiros ou árvores perenes de árvores latifoliadas, que são muito diferentes, como fazer? Este é um problema que não é mais de detecção e delineamento, mas é um problema de classificação e regressão. Então, trata-se de atribuir propriedades para objetos individuais, que são as propriedades, por exemplo, de ser uma espécie ou a quantidade litogênio, pode ser uma espécie, uma classe ou um número em termos de percentual total de nitrogênio. Para chegar lá, utilizarmos dados hiperespectrais, não utilizamos isso para a detecção do problema de detecção, porque nós estávamos olhando essa relação geométrica para distinguir uma árvore de uma outra. Agora, usamos dados hiperespectrais da mesma forma quando nós olhamos um telescópio.
Nós temos alguma coisa semelhante no telescópio, da mesma forma como nós vimos aqui, como assinatura de refletância e, dependendo de onde temos absorção de luz, podemos saber se essa molécula que está lá é de água, ou é uma outra molécula.
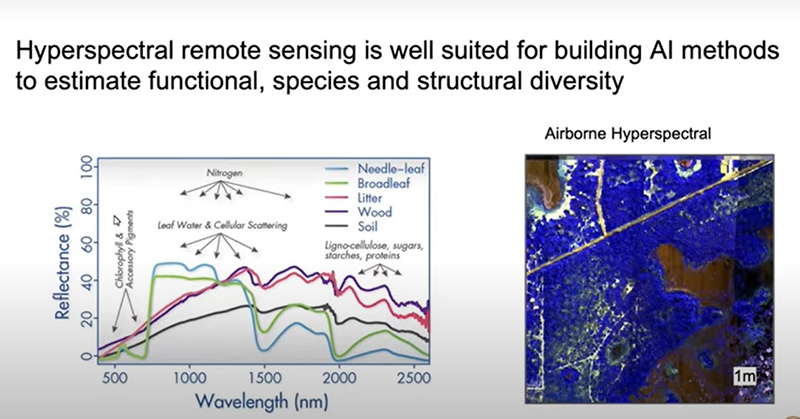
Podemos seguir na mesma linha, podemos trabalhar com essa imagem [acima] e temos um sinal visível para o infravermelho e temos porções do sinal da refletância que nos mostram que há muito mais absorção numa região particular do espectro. E isso nos diz que possivelmente nós temos muito nitrogênio naquela imagem particular. E se nós pudermos tornar mais complexo, podemos pensar em quanto o nitrogênio comparado com madeira ou destruição da árvore. Isso nos dá informações sobre a espécie e outras propriedades também.
Nesse mesmo caso que descrevemos, podemos não utilizar a rede neural convolucional, mas uma forma mais recente e se fazer isso que se chama rede de atenção. A forma de compreender informações para obter dados hiperespectrais é através de uma rede que pode utilizar todas informações e comprimindo não em 26 bandas, mas nos dar um vetor pequeno que pode nos dar uma rede para fazer uma previsão. E aí podemos utilizar dados RGB para obter informações espaciais.
Assim, nós temos uma outra rede que comprime as informações e utiliza uma mágica, que eu não detalhar, que utiliza um conceito muito semelhante do qual falamos. E vocês têm um outro valor, como output que pode atribuir esse vetor para fazer previsões. Vocês também podem utilizar algoritmos para fazer algo mais simples como, por exemplo, regressão linear ou algo mais complexo, modelo hierárquico multinível ou podem utilizar estruturas de redes clássicas.
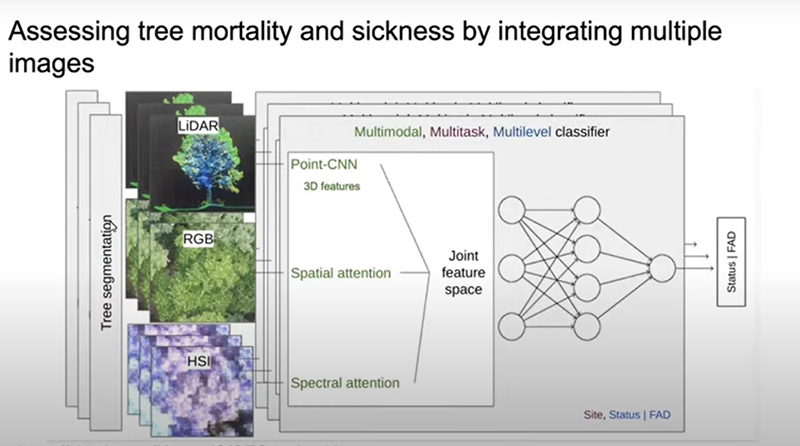
Ou até mesmo vocês podem tentar criar e fazer uma fusão de dados e alavancar as informações de cada conjunto de pontes de dados em particular.
O fato é que cada um desses dados que fato vai permitir a vocês verem propriedades específicas de uma planta. Imagine que se utilizar dados Lidar para, ainda com ajuda de um desfolhar utilizando um RGB, para ver se tem mais verde. Isso vai dizer a vocês qual é o status de saúde da árvore. E utilizar dados hiperespectrais para dar informações sobre a presença de água. E tudo isso pode ir dentro de uma única rede.
E esses algoritmos estão melhorando cada vez mais. A inteligência artificial ajuda não apenas fazer previsões em escala de árvores, mas também ajuda a entender quais são os fatores e processos potenciais que fazem com que as espécies sejam distribuídas. É diferentemente em comparação com outras espécies, mas também permite que os operadores identifiquem lugares onde não conhecemos muito o sistema. Esses sistemas podem nos revelar certezas ou probabilidades estatísticas. Pode nos indicar “tem alguma coisa acontecendo aqui, isto é uma anomalia”. Então, eu posso fazer previsões sobre as espécies nessa determinada região da paisagem.
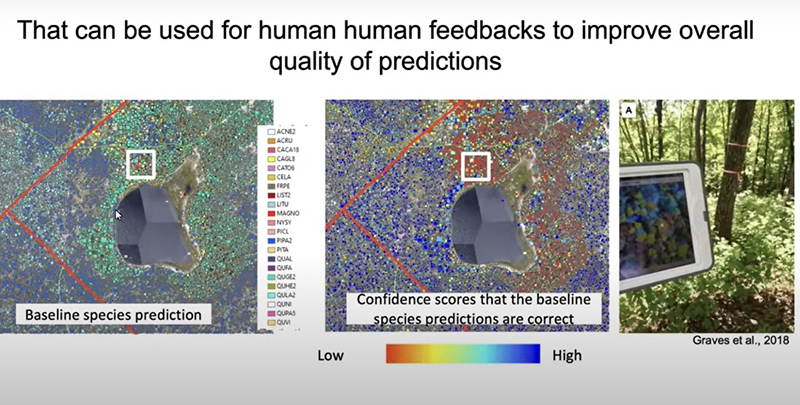
O que se vê em vermelho aqui, por exemplo, [na imagem acima] realmente não é uma boa previsão, há algo de errado, existe uma anomalia. Assim, vocês vão lá e colhem dados para compreender essa realidade apontada ali. Isso é muito útil porque permite que o operador não precise ir coletar dados em todos os lugares. O operador pode escolher locais seletivamente, a partir do que foi indicado. Isso diminui bastante a quantidade de recursos necessários à coleta de dados. Esse campo de coleta de dados é muito útil, os sistemas de IA nos permitem entender aonde devemos ir e focar para a coleta de dados de campo.
É isto que nós temos feito no nosso laboratório, basicamente para identificar como nós podemos escolher dados de árvores individuais para árvores ou espécies raras, espécies que são muito difíceis de encontrar.
Uma coisa em que que a IA está sendo muito útil não é apenas no componente da visão computacional, em monitoramento, mas também prever que na gestão de dados, o manejo baseado em dados. Todos já devem ter ouvido falar em ChatGPT e outras formas de IA, dessa inteligência generativa. Uma característica principal do que é ChatGPT, comparado com outros sistemas, é esta abordagem da aprendizagem de reforço. Podemos utilizar algo semelhante para de fato construir um chat box que pode nos ajudar a tomar decisões de gestão.
E como podemos fazer isso? Nós temos já uma boa ideia de quais são os processos físicos e ecofisiológicos, distribuição e crescimento das espécies. Nós temos esses modelos e temos também essa inteligência artificial baseada em agentes. Imaginem se nós podemos ter um agente, que é o elaborador de políticas, ou o guarda florestal, ou gestor? Fazermos uma interação entre esses sujeitos através de algoritmos e eles interagem entre si no meio ambiente. São as políticas que o agente um faz.
Já o segundo agente vai a mudar a forma como ele maneja floresta e utilizar a previsão que nós conhecemos para as das propriedades de manejo da floresta. Podemos construir infinitas simulações para ver qual é a melhor solução para deixar todo mundo contente. E utilizado não apenas dados históricos, mas ter resultados desejados a políticas para ajudar os elaboradores de políticas públicas para identificar o que pode deixar todos contentes em termos do meio ambiente e preservação.
Trata-se, como na figura [acima], de unir esses dois agentes. Vocês provavelmente têm um animal de estimação. Se o cachorrinho está fazendo algum algo bem, vocês dão uma recompensa. Se ele está fazendo alguma coisa ruim, bom, aí você vai dizer “você foi mal” e ele fica triste. Então, essa classe de algoritmos é treinada de uma forma muito semelhante, onde nós temos uma função de recompensa. O agente ou elaborador de política vai ‘dar um biscoito’, se ele faz a coisa correta. No nosso caso, o que nos deixa contente é a preservação e a conservação do meio ambiente. Assim, vemos como eles podem interagir e ter uma utilidade incomum.
Eu apresentei vários conceitos e muitas informações, mas se você não tem uma ideia de como começar, de como programar, como começar? Bom, se você tiver a oportunidade de fazer uma aula de programação científica, faça. Especialmente em Python ou R, não importa, pode ser uma disciplina da universidade ou não.
Vocês têm informações abertas e livres também. Um lugar que eu sugiro visitarem é o The Carpentries.
É uma programação bem inicial de software, que é uma forma muito fácil de se obter Python, que utiliza a linguagem IA. E se querem dar um passo adiante, sugiro acessarem a Pytorch, que talvez seja, atualmente, a biblioteca mais abrangente de visão computacional e aplicações de IA. A Pytorch realmente é boa sugestão.
Existem vários outros. Todo dia alguém surge com uma ideia colaborativa, mas eu iniciaria com Pytorch.
Se vocês realmente forem mágicos e não sabem como programar Python e ter uma visão computacional de sistemas de IA, mas querem começar com um modelo maior, podem ir para o Hugging face.
É o, digamos, paraíso dos modelos pré-treinados e pré-construídos. E tem também código aberto, vocês podem ter grandes modelos de linguagem, modelos de visão computacional, tudo que vocês puderem imaginar.
E se vocês quiserem construir o seu próprio projeto, a primeira coisa a fazer é ir ao GitHub e ver o que alguém já fez, pois muito provavelmente alguém já teve uma ideia para iniciar um projeto e vocês podem contribuir com outras pessoas e fazer o software que é melhor e de código aberto. Ou simplesmente obter ideias e começar com aquilo que vocês precisam.

O ChatGPT pode ser usado como piloto para ser mais rápido. Ele é especialmente bom para fazer códigos para iniciar. Eu não sugeriria ninguém a iniciar fazendo um software totalmente operacional, mas pelo menos vocês podem ter uma ideia para ir aumentado a produtividade de vocês em dez vezes, porque aí vocês podem ter o backbone das funções de vocês dos data loader de vocês e realmente é muito bom, é um recurso que vocês podem utilizar.
E em termos de dados, há muitos abertos. Toda vez que eu falo sobre isso, as pessoas ficam impressionadas, porque eles acham que ter dados hiperespectrais ou de satélites é algo para laboratórios muito ricos. Isso até foi, mas não é mais. Vocês podem obter dados tridimensionais da Rede Nacional de Observatórios Ecológicos, o NEON.
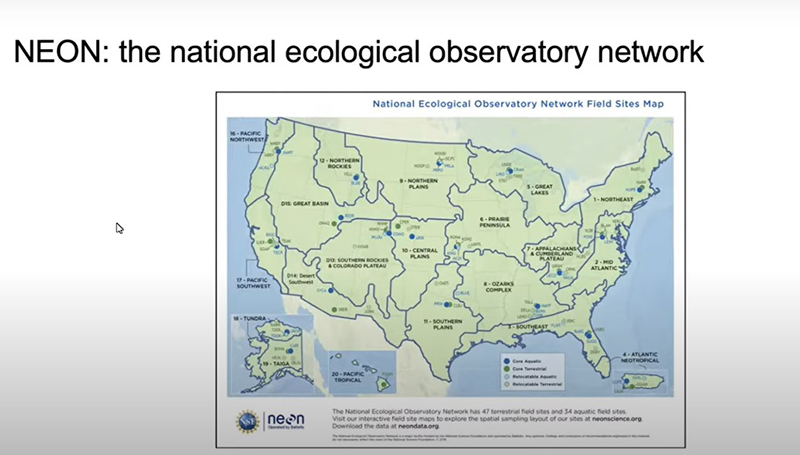
Eles já sobrevoaram todo os Estados Unidos, têm dados hiperespectrais, RGB, validação de dados de campo, dados de animais e plantas. É um recurso enorme e é livre para todos.
Também é tem um portal de dados ali que vocês podem pesquisar. Mas se vocês tiverem interesse em dados satélite, utilizem o Google Earth. É uma fonte muito boa por vários motivos.
Um deles é que são dados satélites disponíveis, abertos e dados também abertos e RGB, e no futuro também vão liberar dados hiperespectrais. O que é incrível é que se você não tem um supercomputador, podem construir um pequeno script em Java, e transformar as ideias de vocês utilizando um ChatGPT e ter o seu código ali.
E tem muitos dados de campo nos nossos arquivos. Um deles é o conjunto de dados da biblioteca de informações rotulados de Biblioteca de Alexandria. Geralmente são dados de pássaros, mamíferos, plantas, peixes, tudo o que vocês puderem pensar.
E por último, tem o Kaggle, que é muito útil para duas coisas: uma é que se vocês forem mágicos de IA podem tentar resolver problemas que realmente são problemas do mundo real. E se vocês forem os melhores nisso vão receber dinheiro para isso. Mas, vocês não têm de pensar apenas em termos de competir, porque podem ter acesso a um código, ideias, e também conjuntos de dados que são dados abertos.
Assista a íntegra da conferência em vídeo: